13.7.4. Entrenar el modelo¶
Con un conjunto de datos etiquetado a mano, el entrenamiento es un flujo guiado en la página Train: fija una versión del conjunto de datos, elige una arquitectura y entrega la ejecución a los servidores de Roboflow.
13.7.4.1. La versión del conjunto de datos¶
Antes de entrenar, Roboflow crea una versión del conjunto de datos – una instantánea congelada de las imágenes más dos transformaciones aplicadas durante la incorporación:
Preprocessing redimensiona cada imagen a la resolución con la que se entrena el modelo. Mantén esa resolución pequeña: la cámara ejecuta modelos pequeños, y un detector entrenado a una resolución modesta cabe en la memoria de la cámara y se ejecuta rápido.
Augmentation sintetiza imágenes de entrenamiento adicionales perturbando las originales – volteos, cambios de brillo y exposición, desenfoque, ruido. Cada aumento enseña al modelo a tolerar una variación real que encontrará en la cámara, lo que aprovecha mucho más un conjunto de datos pequeño capturado a mano.
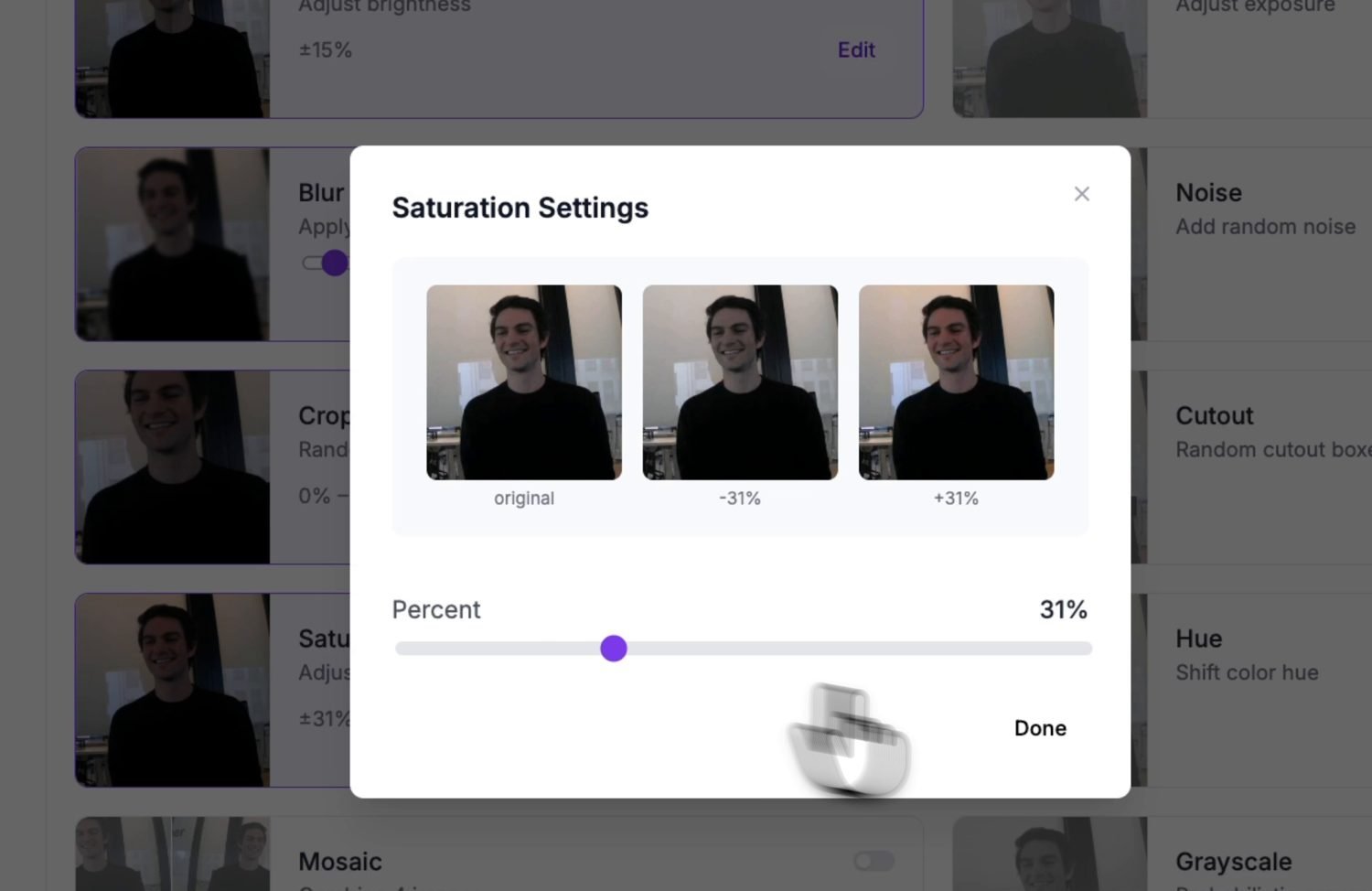
Una vista previa de aumento: cada opción muestra qué le hace a una imagen de muestra antes de aplicarla a la versión.¶
Ajusta los aumentos a las variaciones que la cámara realmente verá. El brillo y la exposición se ganan su lugar – la iluminación cambia constantemente. Omite los que nunca ocurren en tu montaje; una cámara fijada en su sitio nunca ve un volteo vertical, así que el aumento por volteo solo diluye el conjunto de datos.
13.7.4.2. Elegir una arquitectura¶
A continuación, elige la arquitectura del modelo. Roboflow ofrece varias, cada una con un selector de tamaño que equilibra precisión y velocidad.
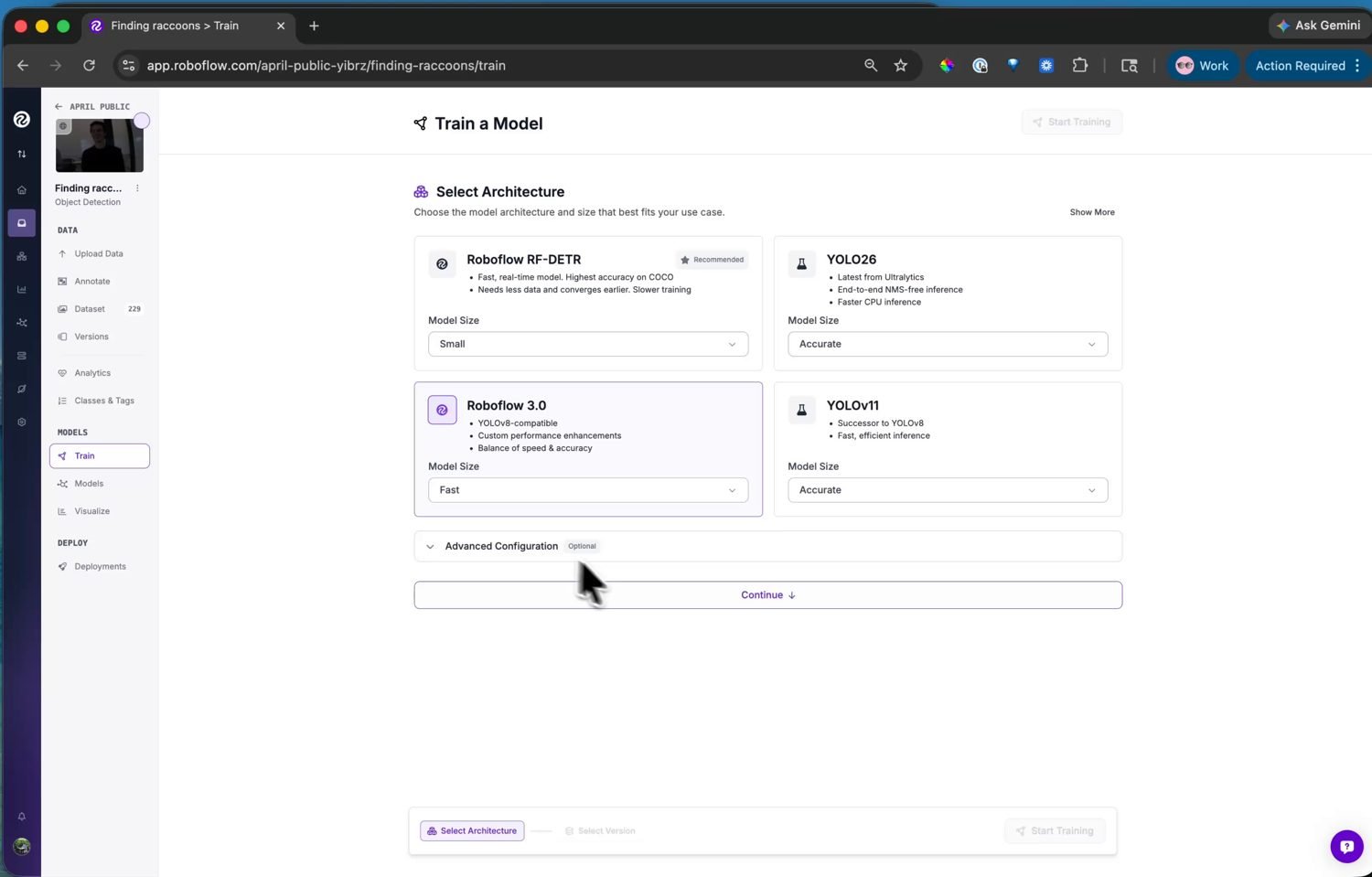
Las opciones de arquitectura – cada una con un selector de tamaño que equilibra precisión y velocidad de inferencia.¶
Para la cámara, elige Roboflow 3.0. Por dentro es YOLOv8, y la cámara incluye un postprocesador YOLOv8 en ml.postprocessing.ultralytics, de modo que su salida se decodifica sin código adicional por tu parte. Elige el tamaño Fast – cabe en la memoria de la cámara y se ejecuta a una velocidad de fotogramas utilizable.
13.7.4.3. Ejecutar el entrenamiento¶
Inicia la ejecución y el entrenamiento ocurre en los servidores de Roboflow – normalmente bastante menos de una hora para un conjunto de datos pequeño, con un correo electrónico cuando termina. La página de la versión muestra entonces las gráficas de entrenamiento y las métricas de precisión: mAP, precisión y exhaustividad.
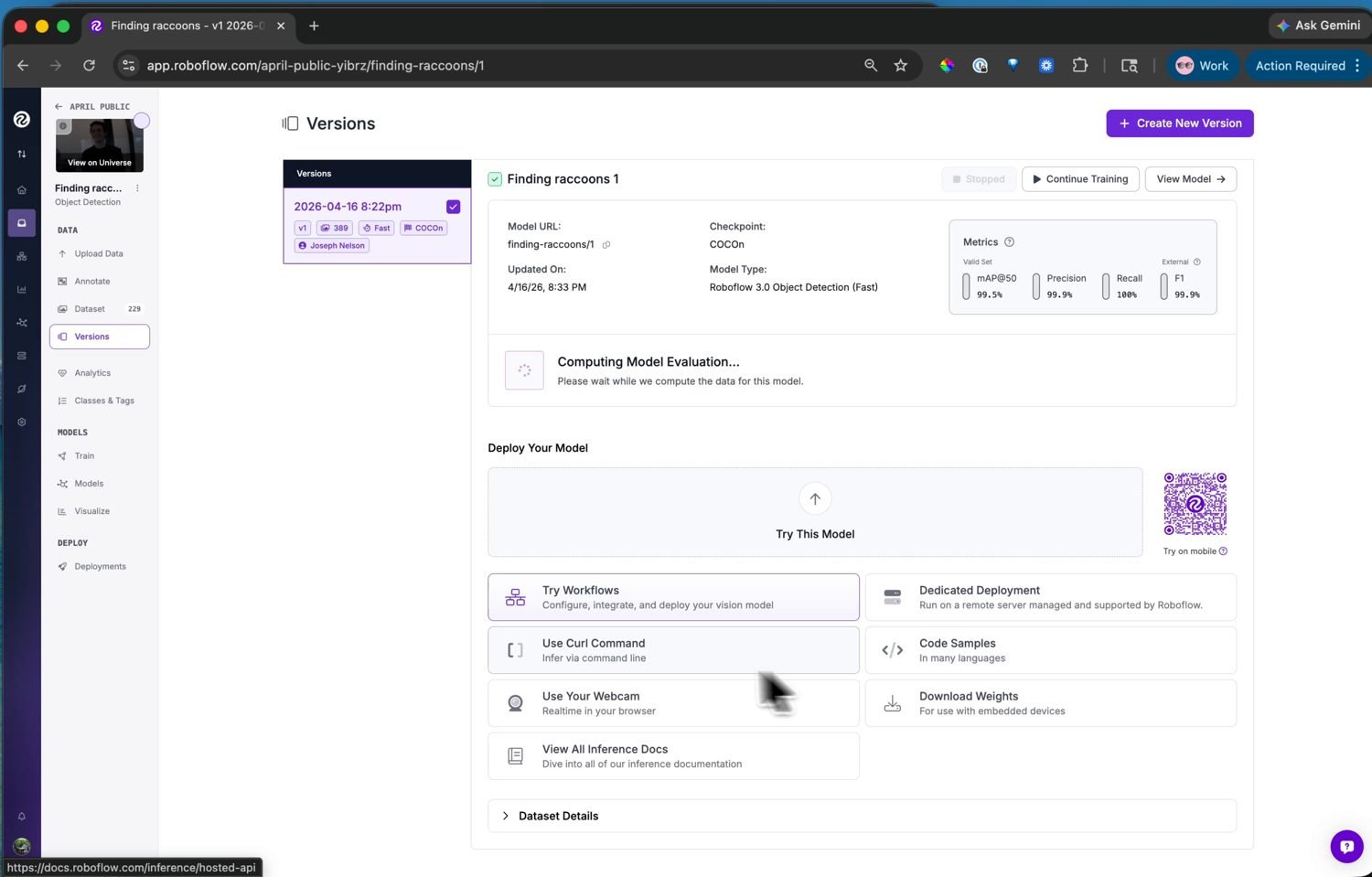
El modelo entrenado con sus métricas de precisión. Desde aquí, la página Visualize también lo ejecuta sobre imágenes de prueba o una webcam para una comprobación rápida.¶
Si los números son buenos, el modelo está listo para desplegar. Si no, la solución suele ser más datos o datos más variados – captura otro clip, etiquétalo y entrena una nueva versión.