Zarządzanie pamięcią¶
W przeciwieństwie do języków programowania takich jak C/C++, MicroPython ukrywa przed programistą szczegóły zarządzania pamięcią, oferując automatyczne zarządzanie pamięcią. Automatyczne zarządzanie pamięcią to technika stosowana przez systemy operacyjne lub aplikacje w celu automatycznego zarządzania przydzielaniem i zwalnianiem pamięci. Eliminuje to problemy takie jak zapomnienie o zwolnieniu pamięci przydzielonej obiektowi. Automatyczne zarządzanie pamięcią pozwala również uniknąć krytycznego problemu używania pamięci, która została już zwolniona. Automatyczne zarządzanie pamięcią przybiera wiele form, a jedną z nich jest odśmiecanie pamięci (garbage collection, GC).
Garbage collector ma zazwyczaj dwa zadania;
Przydzielanie nowych obiektów w dostępnej pamięci.
Zwalnianie nieużywanej pamięci.
Istnieje wiele algorytmów GC, ale MicroPython stosuje strategię Mark and Sweep do zarządzania pamięcią. Algorytm ten ma fazę oznaczania (mark), która przechodzi przez stertę, oznaczając wszystkie żywe obiekty, podczas gdy faza zamiatania (sweep) przechodzi przez stertę, odzyskując wszystkie nieoznaczone obiekty.
Funkcjonalność odśmiecania pamięci w MicroPython jest dostępna poprzez wbudowany moduł gc:
>>> x = 5
>>> x
5
>>> import gc
>>> gc.enable()
>>> gc.mem_alloc()
1312
>>> gc.mem_free()
2071392
>>> gc.collect()
19
>>> gc.disable()
>>>
Nawet gdy wywołano gc.disable(), odśmiecanie można wyzwolić za pomocą gc.collect().
Pamięć MicroPython z poziomu kodu C¶
Świadomość działania garbage collectora jest potrzebna podczas pisania kodu C, który przydziela pamięć ze „sterty Pythona” (tzn. funkcje m_malloc(), m_malloc0(), m_free() itp.).
Faza oznaczania garbage collectora skanuje w poszukiwaniu żywych wskaźników do pamięci sterty, zaczynając od następujących korzeni:
Stos głównego środowiska uruchomieniowego Pythona (lub REPL).
Stosy każdego „wątku Pythona”, dla portów implementujących wątki Pythona na bazie natywnych wątków lub zadań systemu operacyjnego.
„Wskaźniki korzeniowe” (root pointers) zdefiniowane w kodzie C za pomocą makra
MP_REGISTER_ROOT_POINTER. Jest to zalecany sposób utrzymywania statycznie zakresowanych wskaźników do sterty Pythona.Śledzone alokacje wykonane za pomocą funkcji
m_tracked_calloc(),m_tracked_reallocim_tracked_free(). Te specjalne funkcje pozwalają przydzielić blok pamięci, który jest zawsze uznawany przez garbage collector za żywy. Podobnie jak w przypadku alokacji pamięci w C, pamięć ta jest zwalniana wyłącznie przez wywołaniem_tracked_free()lub przez miękki reset. Każda śledzona alokacja wiąże się z niewielkim zużyciem pamięci i narzutem czasu wykonania. Funkcja ta nie jest domyślnie włączona na wszystkich portach.
Następnie garbage collector rekurencyjnie skanuje i oznacza całą pamięć wskazywaną przez wskaźniki korzeniowe, aż do wyczerpania wszystkich adresów. To wystarcza, aby odnaleźć wszystkie obiekty Pythona, które są nadal używane przez środowisko uruchomieniowe MicroPython.
Jednak następująca pamięć nie będzie skanowana przez garbage collector i może zostać zwolniona przedwcześnie:
Statyczne lub globalne zmienne C zawierające wskaźniki do pamięci sterty.
Wskaźniki, które nie wskazują na „początek” (head) przydzielonego bufora (tzn. na dokładny adres zwrócony przez
m_malloc()), lecz na adres wewnątrz przydzielonego bufora (na przykład wskaźnik do zagnieżdżonej struktury). Ze względów wydajnościowych garbage collector w takich przypadkach nie oznacza otaczającego bufora.Stos dowolnego wątku lub zadania RTOS, który nie wykonuje kodu Pythona ani nie został ręcznie zarejestrowany jako „wątek Pythona” (dla portów obsługujących natywne wątki lub zadania).
Sposoby unikania użycia pamięci po zwolnieniu (use-after-free) w tych scenariuszach:
Użyj API śledzonej alokacji
m_tracked_calloc(),m_tracked_realloc()im_tracked_free().Zarejestruj wskaźnik korzeniowy (patrz wyżej) zamiast przechowywać wskaźnik w zmiennej statycznej.
Przebuduj kod, na przykład tworząc API, w którym kod Pythona inicjalizuje pojedynczy obiekt singleton Pythona (zaimplementowany w C), przechowujący wszystkie istotne wskaźniki, zamiast trzymać je w zmiennych statycznych.
Informacja
Miękki reset zawsze czyści stertę Pythona i zwalnia całą pamięć. Ważne jest, aby po miękkim resecie nie przechowywać żadnych wskaźników do sterty, ponieważ staną się one zawisłymi wskaźnikami do zwolnionej pamięci.
Niektóre porty obsługują również „stertę C” (patrz Dynamiczna alokacja pamięci w C); w takim przypadku można przydzielić pamięć, która pozostanie ważna po miękkim resecie, wywołując standardowe funkcje C malloc itp.
Model obiektowy¶
Wszystkie obiekty MicroPython są reprezentowane przez typ danych mp_obj_t. Ma on zazwyczaj rozmiar słowa (tzn. taki sam jak wskaźnik na docelowej architekturze) i typowo może być 32-bitowy (STM32, RP2, nRF, Unix x86) lub 64-bitowy (Unix x64). Dla pewnych reprezentacji obiektów może być również większy niż rozmiar słowa, na przykład OBJ_REPR_D ma 64-bitowy mp_obj_t na architekturze 32-bitowej.
mp_obj_t reprezentuje obiekt MicroPython, na przykład liczbę całkowitą, zmiennoprzecinkową, typ, słownik lub instancję klasy. Niektóre obiekty, takie jak wartości logiczne i małe liczby całkowite, mają swoją wartość przechowywaną bezpośrednio w wartości mp_obj_t i nie wymagają dodatkowej pamięci. Inne obiekty mają swoją wartość przechowywaną gdzie indziej w pamięci (na przykład na odśmiecanej stercie), a ich mp_obj_t zawiera wskaźnik do tej pamięci. Część mp_obj_t stanowi znacznik (tag), który informuje, jakiego typu jest dany obiekt.
Szczegółowe informacje na temat dostępnych reprezentacji znajdują się w py/mpconfig.h.
Znacznikowanie wskaźników (pointer tagging)
Ponieważ wskaźniki są wyrównane do słowa, gdy są przechowywane w mp_obj_t, najmłodsze bity tego uchwytu obiektu będą równe zero. Na przykład na architekturze 32-bitowej dwa najmłodsze bity będą zerowe:
********|********|********|******00
Bity te są zarezerwowane do celów przechowywania znacznika. Znacznik przechowuje dodatkowe informacje zamiast wprowadzania nowego pola do przechowywania tych informacji w obiekcie, co mogłoby być nieefektywne. W MicroPython znacznik informuje, czy mamy do czynienia z małą liczbą całkowitą, internowanym (małym) łańcuchem znaków czy konkretnym obiektem, przy czym do każdego z nich stosuje się inną semantykę.
Dla małych liczb całkowitych odwzorowanie wygląda tak:
********|********|********|*******1
Gdzie gwiazdki przechowują faktyczną wartość całkowitą. Dla internowanego łańcucha znaków lub obiektu bezpośredniego (np. True) układ wartości mp_obj_t wygląda odpowiednio:
********|********|********|*****010
********|********|********|*****110
Natomiast konkretny obiekt, który nie jest żadnym z powyższych, przybiera postać:
********|********|********|******00
Gwiazdki odpowiadają tutaj adresowi konkretnego obiektu w pamięci.
Alokacja obiektów¶
Wartość małej liczby całkowitej jest przechowywana bezpośrednio w mp_obj_t i będzie przydzielana w miejscu, a nie na stercie czy gdzie indziej. W związku z tym tworzenie małych liczb całkowitych nie wpływa na stertę. Podobnie jest w przypadku internowanych łańcuchów znaków, których dane tekstowe są już przechowywane gdzie indziej, oraz wartości bezpośrednich takich jak None, False i True.
Wszystko inne, co jest konkretnym obiektem, jest przydzielane na stercie, a jego struktura jest taka, że w nagłówku obiektu zarezerwowane jest pole do przechowywania typu obiektu.
+++++++++++
+ +
+ type + object header
+ +
+++++++++++
+ + object items
+ +
+ +
+++++++++++
Najmniejszą jednostką alokacji na stercie jest blok, który ma rozmiar czterech słów maszynowych (16 bajtów na maszynie 32-bitowej, 32 bajty na maszynie 64-bitowej). Inna struktura, również przydzielona na stercie, śledzi alokację obiektów w każdym bloku. Struktura ta nosi nazwę bitmapy.
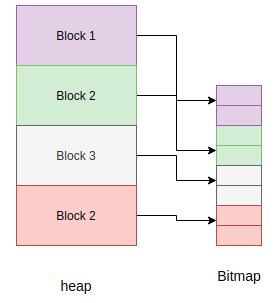
Bitmapa śledzi, czy blok jest „wolny”, czy „w użyciu”, i wykorzystuje dwa bity do śledzenia tego stanu dla każdego bloku.
Garbage collector typu mark-sweep zarządza obiektami przydzielonymi na stercie, a także wykorzystuje bitmapę do oznaczania obiektów, które są nadal w użyciu. Pełną implementację tych szczegółów można znaleźć w py/gc.c.
Alokacja: układ sterty
Sterta jest zorganizowana tak, że składa się z bloków w pulach. Blok może mieć różne właściwości:
ATB (allocation table byte): Jeśli ustawiony, to blok jest blokiem normalnym
FREE: Wolny blok
HEAD: Początek łańcucha bloków
TAIL: W ogonie łańcucha bloków
MARK : Oznaczony blok początkowy
FTB (finaliser table byte): Jeśli ustawiony, to blok ma finalizator