Gestão de Memória¶
Ao contrário de linguagens de programação como C/C++, o MicroPython oculta os detalhes de gestão de memória do programador ao suportar gestão automática de memória. A gestão automática de memória é uma técnica utilizada por sistemas operativos ou aplicações para gerir automaticamente a alocação e a libertação de memória. Isto elimina problemas como o esquecimento de libertar a memória alocada a um objeto. A gestão automática de memória também evita o problema crítico de utilizar memória que já foi libertada. A gestão automática de memória assume várias formas, sendo uma delas a recolha de lixo (GC).
O coletor de lixo tem normalmente duas responsabilidades:
Alocar novos objetos na memória disponível.
Libertar a memória não utilizada.
Existem muitos algoritmos de GC, mas o MicroPython utiliza a política Mark and Sweep para gerir a memória. Este algoritmo tem uma fase de marcação que percorre o heap marcando todos os objetos vivos, enquanto a fase de varrimento percorre o heap recuperando todos os objetos não marcados.
A funcionalidade de recolha de lixo no MicroPython está disponível através do módulo embutido gc:
>>> x = 5
>>> x
5
>>> import gc
>>> gc.enable()
>>> gc.mem_alloc()
1312
>>> gc.mem_free()
2071392
>>> gc.collect()
19
>>> gc.disable()
>>>
Mesmo quando gc.disable() é invocado, a recolha pode ser desencadeada com gc.collect().
Memória MicroPython a partir de código C¶
É necessário ter consciência do coletor de lixo ao escrever código C que aloca memória a partir do «Python heap» (ou seja, as funções m_malloc(), m_malloc0(), m_free(), etc).
A fase de marcação do coletor de lixo procura ponteiros vivos para a memória do heap a partir das seguintes raízes:
A pilha do tempo de execução principal do Python (ou REPL).
As pilhas de cada «Python thread», para portas que implementam threads Python em cima de threads ou tarefas nativas do sistema operativo.
Os «ponteiros raiz» definidos em código C utilizando a macro
MP_REGISTER_ROOT_POINTER. Estes são a forma recomendada de ter ponteiros com âmbito estático para o Python heap.Alocações rastreadas feitas com as funções
m_tracked_calloc(),m_tracked_reallocem_tracked_free(). Estas funções especiais permitem alocar um bloco de memória que é sempre considerado vivo pelo coletor de lixo. De forma semelhante à alocação de memória em C, esta memória só é libertada ao chamarm_tracked_free()ou por reinicialização suave. Existe uma pequena sobrecarga de utilização de memória e de tempo de execução para cada alocação rastreada. Esta funcionalidade não está ativa por omissão em todas as portas.
O coletor de lixo percorre e marca recursivamente toda a memória apontada pelos ponteiros raiz, até todos os endereços serem esgotados. Isto é suficiente para encontrar todos os objetos Python que ainda estão a ser utilizados pelo tempo de execução do MicroPython.
No entanto, a seguinte memória não será varrida pelo coletor de lixo e poderá ser libertada prematuramente:
Variáveis C estáticas ou globais que contêm ponteiros para a memória do heap.
Ponteiros que não apontam para o «cabeçalho» de um buffer alocado (ou seja, para o endereço exato devolvido por
m_malloc()), mas sim para um endereço dentro do buffer alocado (por exemplo, um ponteiro para uma struct aninhada). Por razões de desempenho, o coletor de lixo não marca o buffer envolvente nestes casos.A pilha de qualquer thread ou tarefa RTOS que não esteja a executar código Python ou que não esteja manualmente registada como «Python thread» (para portas que suportam threads ou tarefas nativas).
Formas de evitar o uso após libertação nestes cenários:
Utilizar a API de alocação rastreada
m_tracked_calloc(),m_tracked_realloc()em_tracked_free().Registar um ponteiro raiz (ver acima), em vez de armazenar um ponteiro numa variável estática.
Reestruturar o código, por exemplo, tendo uma API onde o código Python inicializa um objeto Python singleton (implementado em C) que contém todos os ponteiros relevantes, em vez de os ter em variáveis estáticas.
Nota
Reset suave limpa sempre o Python heap e liberta toda a memória. É importante não manter quaisquer ponteiros para o heap após uma reinicialização suave, pois estes tornar-se-ão ponteiros pendentes para memória libertada.
Algumas portas suportam também um «C heap» (ver Alocação Dinâmica de Memória em C), caso em que pode alocar memória que permanecerá válida após uma reinicialização suave chamando as funções C padrão malloc, etc.
O modelo de objetos¶
Todos os objetos MicroPython são referenciados pelo tipo de dados mp_obj_t. Este tem normalmente o tamanho de uma palavra (ou seja, o mesmo tamanho que um ponteiro na arquitetura alvo), podendo ser tipicamente de 32 bits (STM32, RP2, nRF, Unix x86) ou 64 bits (Unix x64). Pode também ser maior que uma palavra para certas representações de objetos; por exemplo, OBJ_REPR_D tem um mp_obj_t de 64 bits numa arquitetura de 32 bits.
Um mp_obj_t representa um objeto MicroPython, por exemplo um inteiro, float, tipo, dict ou instância de classe. Alguns objetos, como booleanos e pequenos inteiros, têm o seu valor armazenado diretamente no valor mp_obj_t e não requerem memória adicional. Outros objetos têm o seu valor armazenado noutro local da memória (por exemplo, no heap gerido pelo coletor de lixo) e o seu mp_obj_t contém um ponteiro para essa memória. Uma parte do mp_obj_t é a etiqueta que indica que tipo de objeto é.
Consulte py/mpconfig.h para os detalhes específicos das representações disponíveis.
Marcação de ponteiros
Como os ponteiros estão alinhados por palavras, quando são armazenados num mp_obj_t os bits inferiores deste identificador de objeto serão zero. Por exemplo, numa arquitetura de 32 bits os 2 bits inferiores serão zero:
********|********|********|******00
Estes bits estão reservados para fins de armazenamento de uma etiqueta. A etiqueta armazena informação extra em oposição à introdução de um novo campo para armazenar essa informação no objeto, o que poderia ser ineficiente. No MicroPython, a etiqueta indica se estamos a lidar com um pequeno inteiro, uma string internada (pequena) ou um objeto concreto, aplicando-se diferentes semânticas a cada um deles.
Para pequenos inteiros, o mapeamento é este:
********|********|********|*******1
Onde os asteriscos contêm o valor inteiro real. Para uma string internada ou um objeto imediato (por exemplo, True), o layout do valor mp_obj_t é, respetivamente:
********|********|********|*****010
********|********|********|*****110
Enquanto um objeto concreto que não é nenhum dos anteriores assume a forma:
********|********|********|******00
As estrelas aqui correspondem ao endereço do objeto concreto na memória.
Alocação de objetos¶
O valor de um pequeno inteiro é armazenado diretamente no mp_obj_t e será alocado no local, não no heap ou noutro sítio. Assim, a criação de pequenos inteiros não afeta o heap. O mesmo se aplica às strings internadas que já têm os seus dados textuais armazenados noutro local, e a valores imediatos como None, False e True.
Tudo o resto que é um objeto concreto é alocado no heap e a sua estrutura de objeto é tal que um campo está reservado no cabeçalho do objeto para armazenar o tipo do objeto.
+++++++++++
+ +
+ type + object header
+ +
+++++++++++
+ + object items
+ +
+ +
+++++++++++
A menor unidade de alocação do heap é um bloco, que tem o tamanho de quatro palavras de máquina (16 bytes numa máquina de 32 bits, 32 bytes numa máquina de 64 bits). Outra estrutura também alocada no heap regista a alocação de objetos em cada bloco. Esta estrutura é denominada bitmap.
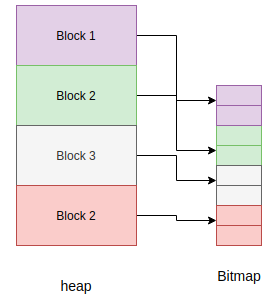
O bitmap regista se um bloco está «livre» ou «em uso» e utiliza dois bits para rastrear este estado para cada bloco.
O coletor de lixo mark-sweep gere os objetos alocados no heap, e também utiliza o bitmap para marcar objetos que ainda estão em uso. Consulte py/gc.c para a implementação completa destes detalhes.
Alocação: layout do heap
O heap está organizado de forma a consistir em blocos em grupos. Um bloco pode ter diferentes propriedades:
ATB (byte da tabela de alocação): Se definido, então o bloco é um bloco normal
FREE: Bloco livre
HEAD: Cabeça de uma cadeia de blocos
TAIL: Na cauda de uma cadeia de blocos
MARK: Bloco cabeça marcado
FTB (byte da tabela de finalizadores): Se definido, então o bloco tem um finalizador