13.7.3. Rotulando as imagens¶
Um detector de objetos aprende a partir de exemplos rotulados: cada imagem de treinamento precisa de uma caixa ao redor de cada objeto-alvo, marcada com sua classe. Rotular centenas de quadros à mão é lento, então o Roboflow automatiza essa tarefa.
13.7.3.1. Auto Label¶
Na página Annotate, o Auto Label aciona um modelo de fundação guiado por texto: você descreve cada classe em palavras e ele encontra e desenha caixas ao redor desses objetos em todo o lote. Adicione uma classe para cada coisa que você quer detectar – stuffed raccoon toy e person para ensinar o modelo a ignorar – visualize o resultado em algumas imagens de teste e ajuste o limiar de confiança de cada classe até que as caixas fiquem onde deveriam.
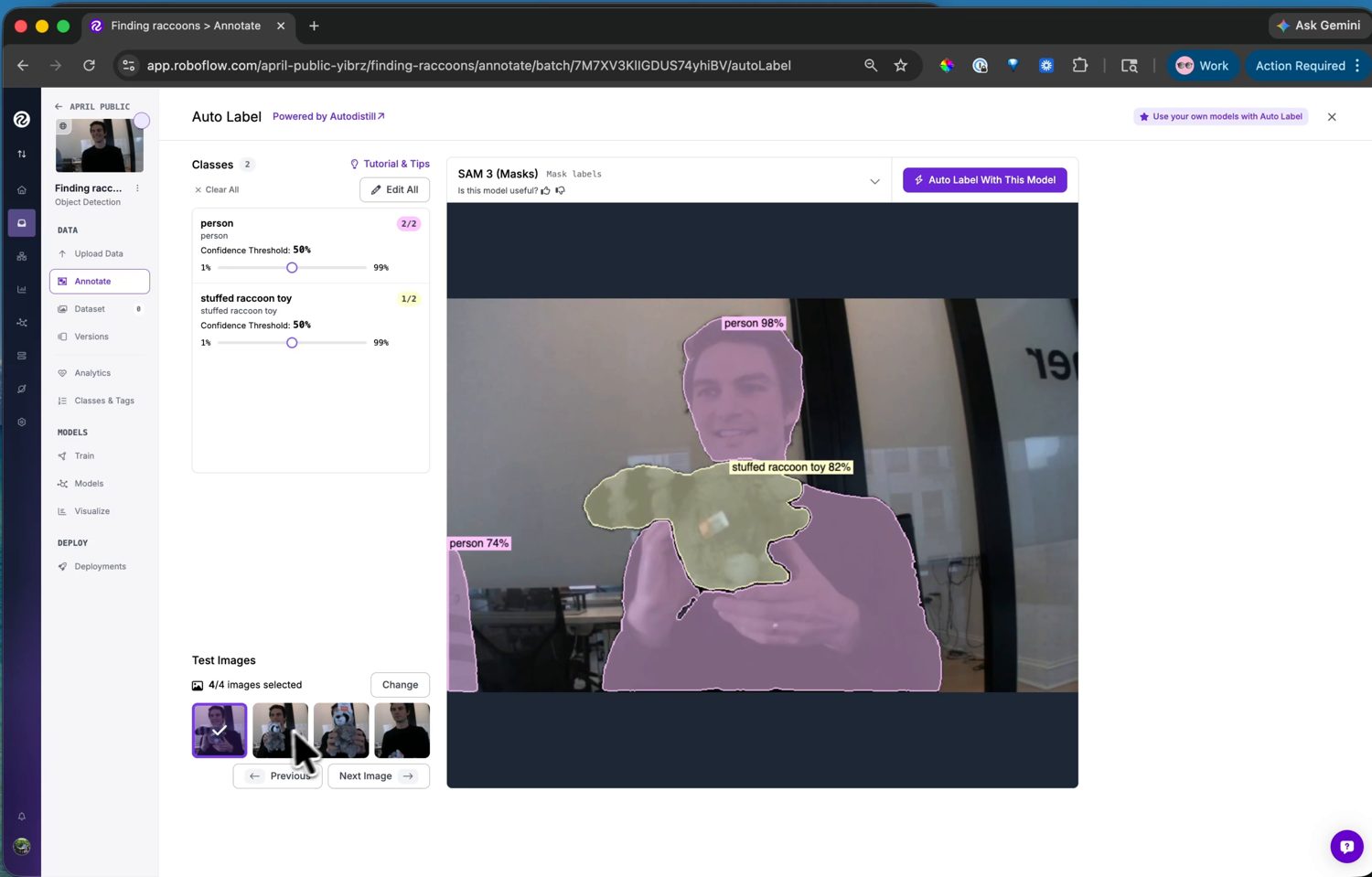
O Auto Label encontra as classes a partir dos prompts de texto e rotula o lote – visualize e ajuste os limiares antes de executá-lo em todas as imagens.¶
Execute-o no lote e então revise: examine as imagens rotuladas, corrija as poucas que o modelo errou e exclua as caixas que ele inventou. O Auto Label faz o trabalho pesado; a passagem de revisão captura seus erros.
13.7.3.2. Adicionando ao conjunto de dados¶
As imagens rotuladas vão para o conjunto de dados com uma divisão train / valid / test. A divisão é a forma como a acurácia do modelo é medida: ele treina nas imagens de treinamento, ajusta-se contra o conjunto de validação e é avaliado nas imagens de teste que nunca viu durante o treinamento. A divisão padrão funciona – aceite-a e o conjunto de dados está pronto para treinar.