13.7.3. 為影像加上標籤¶
物件偵測器是從已標記的範例中學習的:每張訓練影像都需要在每個目標物件周圍框上一個方框,並標記其類別。手動為數百個影格加上標籤很慢,因此 Roboflow 將此流程自動化。
13.7.3.1. Auto Label¶
在 Annotate 頁面上,Auto Label 會驅動一個由文字提示的基礎模型:你用文字描述每個類別,它便會在整個批次中找出並框出那些物件。為每個你想偵測的事物新增一個類別——stuffed raccoon toy,以及 person 以教導模型要忽略什麼——在幾張測試影像上預覽結果,並調整每個類別的信心閾值,直到方框落在應有的位置為止。
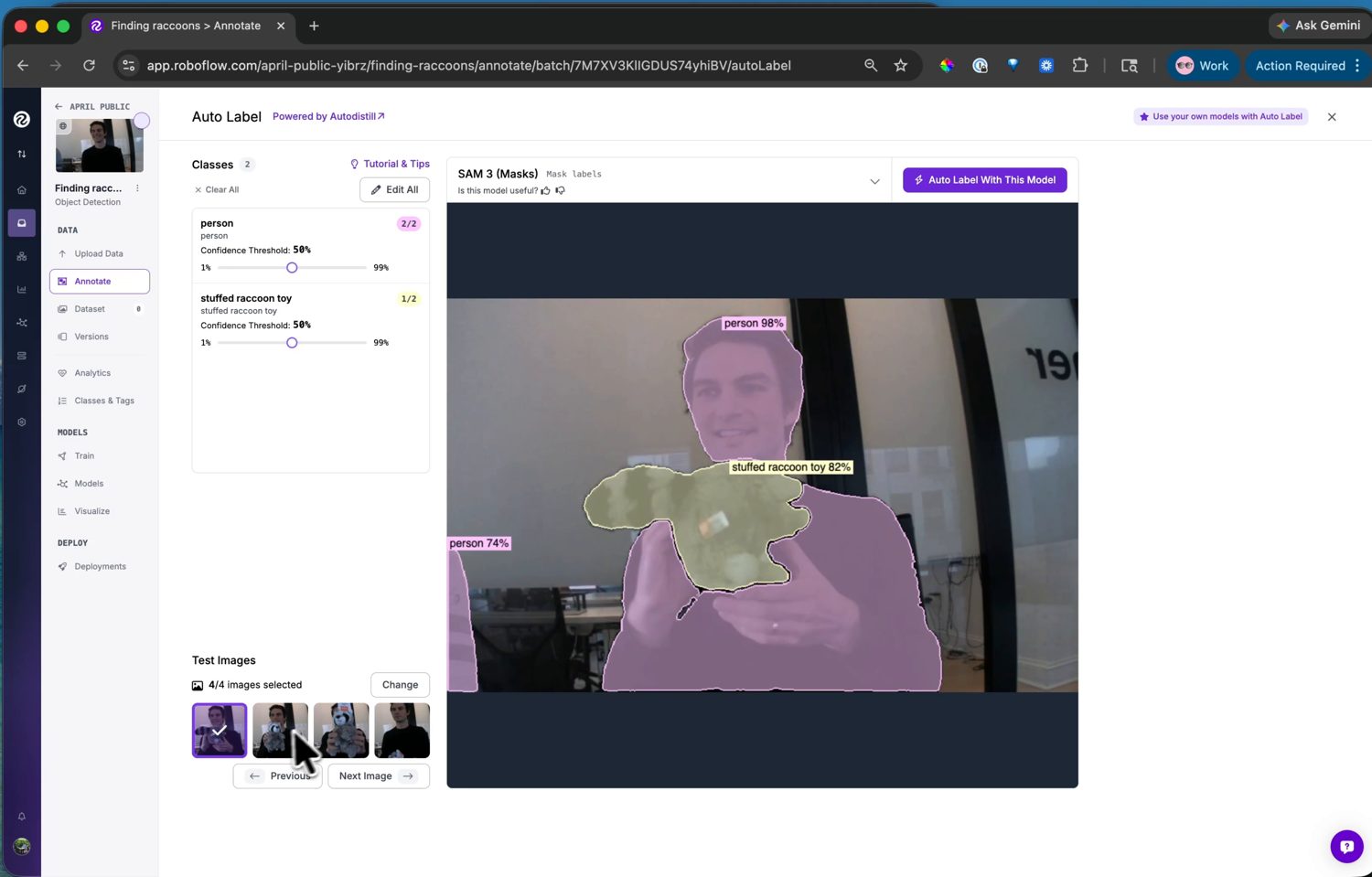
Auto Label 會從文字提示找出類別並為批次加上標籤——在對每張影像執行之前,先預覽並調校閾值。¶
對批次執行它,然後進行檢視:掃視已標記的影像,修正少數模型出錯之處,並刪除它憑空產生的方框。Auto Label 負責大量的工作;檢視這一步則能抓出它的錯誤。
13.7.3.2. 加入資料集¶
已標記的影像會以 train / valid / test 分割方式移入資料集。此分割是衡量模型準確度的方式:模型在訓練影像上進行訓練,針對驗證集進行調校,並以它在訓練期間從未見過的測試影像來評分。預設的分割就很適用——接受它,資料集便準備好可以訓練了。