13.7.4. Das Modell trainieren¶
Mit einem beschrifteten Datensatz in der Hand ist das Training ein geführter Ablauf auf der Seite Train: Legen Sie eine Datensatzversion fest, wählen Sie eine Architektur und übergeben Sie den Lauf an Roboflows Server.
13.7.4.1. Die Datensatzversion¶
Vor dem Training erstellt Roboflow eine Datensatz-Version – einen eingefrorenen Schnappschuss der Bilder plus zwei Transformationen, die beim Hinzufügen angewendet werden:
Preprocessing skaliert jedes Bild auf die Auflösung, mit der das Modell trainiert. Halten Sie diese Auflösung klein: Die Kamera führt kleine Modelle aus, und ein bei einer moderaten Auflösung trainierter Detektor passt in den Speicher der Kamera und läuft schnell.
Augmentation synthetisiert zusätzliche Trainingsbilder, indem sie die Originale variiert – Spiegelungen, Helligkeits- und Belichtungsverschiebungen, Unschärfe, Rauschen. Jede Augmentation lehrt das Modell, eine reale Variation zu tolerieren, der es auf der Kamera begegnen wird, was einen kleinen, von Hand aufgenommenen Datensatz deutlich erweitert.
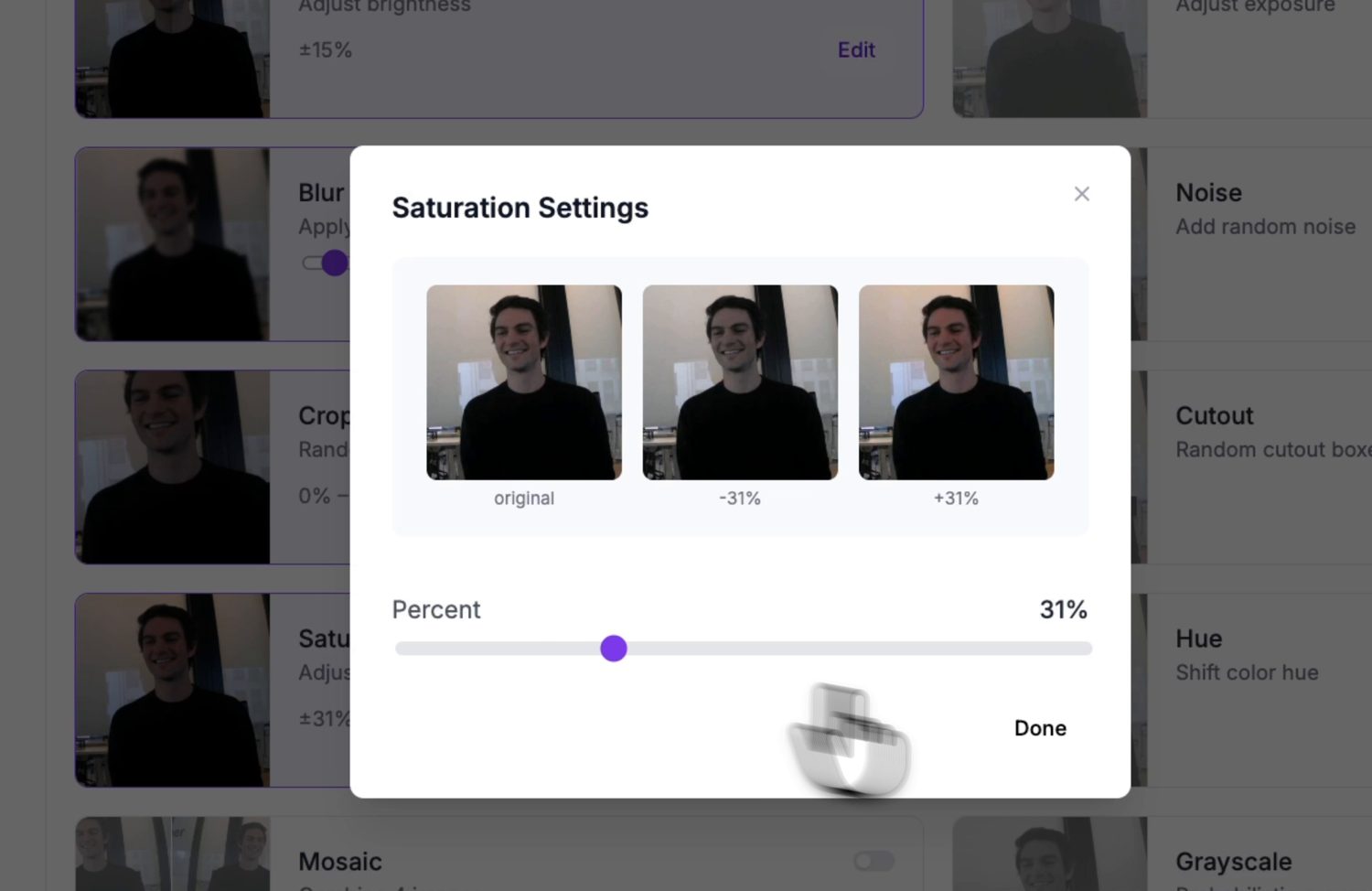
Eine Augmentationsvorschau: Jede Option zeigt, was sie mit einem Beispielbild macht, bevor Sie sie für die Version übernehmen.¶
Passen Sie die Augmentationen an Variationen an, die die Kamera tatsächlich sehen wird. Helligkeit und Belichtung verdienen ihren Platz – die Beleuchtung ändert sich ständig. Überspringen Sie solche, die in Ihrem Aufbau nie vorkommen; eine fest montierte Kamera sieht nie eine vertikale Spiegelung, also verwässert eine Spiegelungs-Augmentation den Datensatz nur.
13.7.4.2. Eine Architektur wählen¶
Wählen Sie als Nächstes die Modellarchitektur. Roboflow bietet mehrere an, jede mit einem Größenwähler, der Genauigkeit gegen Geschwindigkeit abwägt.
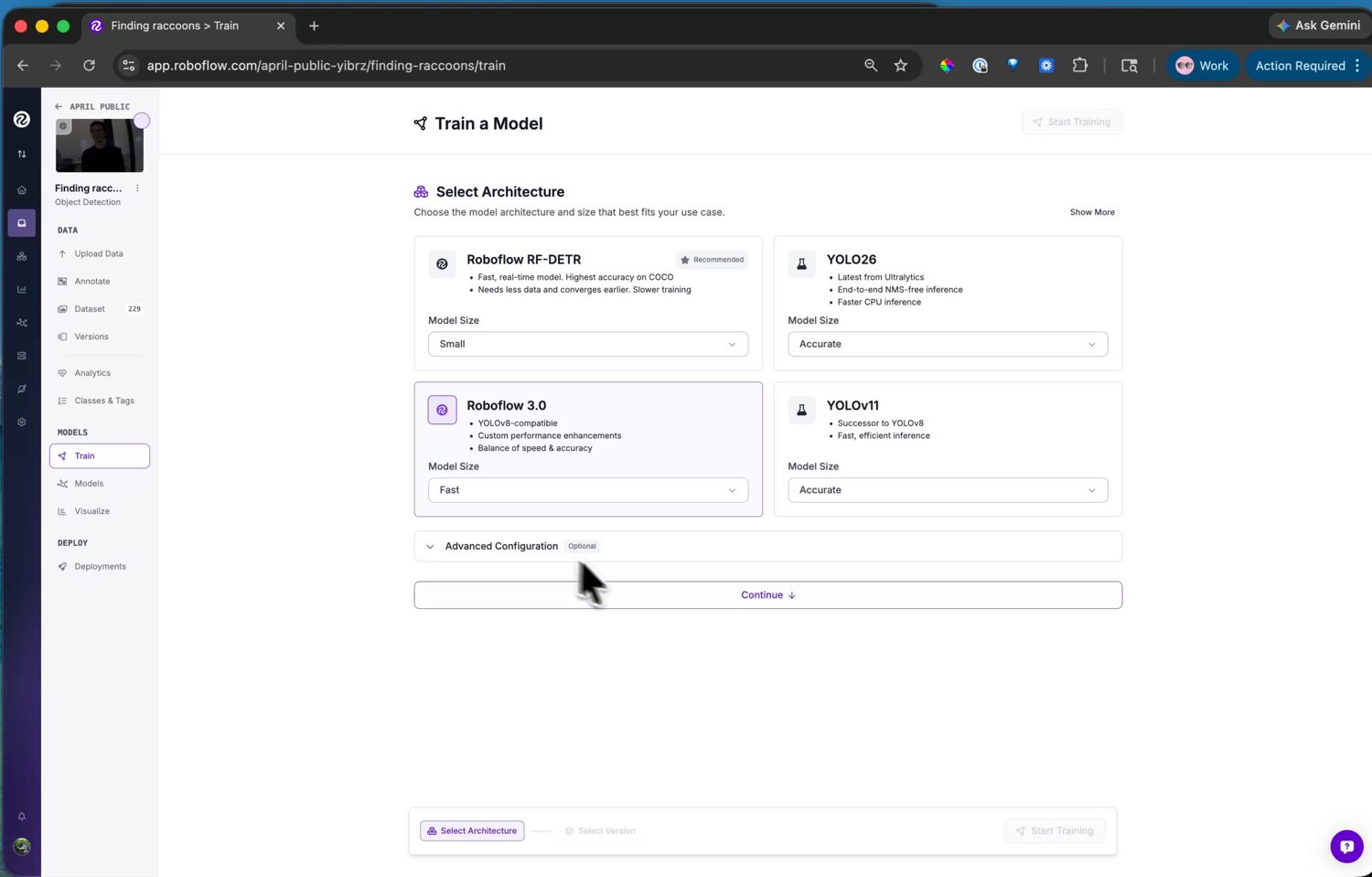
Die Architekturauswahl – jede mit einem Größenwähler, der Genauigkeit gegen Inferenzgeschwindigkeit abwägt.¶
Wählen Sie für die Kamera Roboflow 3.0. Unter der Haube ist es YOLOv8, und die Kamera liefert einen YOLOv8-Post-Prozessor in ml.postprocessing.ultralytics mit, sodass seine Ausgabe ohne zusätzlichen Code auf Ihrer Seite decodiert wird. Wählen Sie die Größe Fast – sie passt in den Speicher der Kamera und läuft mit einer nutzbaren Bildrate.
13.7.4.3. Das Training ausführen¶
Starten Sie den Lauf, und das Training erfolgt auf Roboflows Servern – üblicherweise deutlich unter einer Stunde für einen kleinen Datensatz, mit einer E-Mail, wenn es fertig ist. Die Versionsseite zeigt dann die Trainingsdiagramme und die Genauigkeitsmetriken: mAP, Precision und Recall.
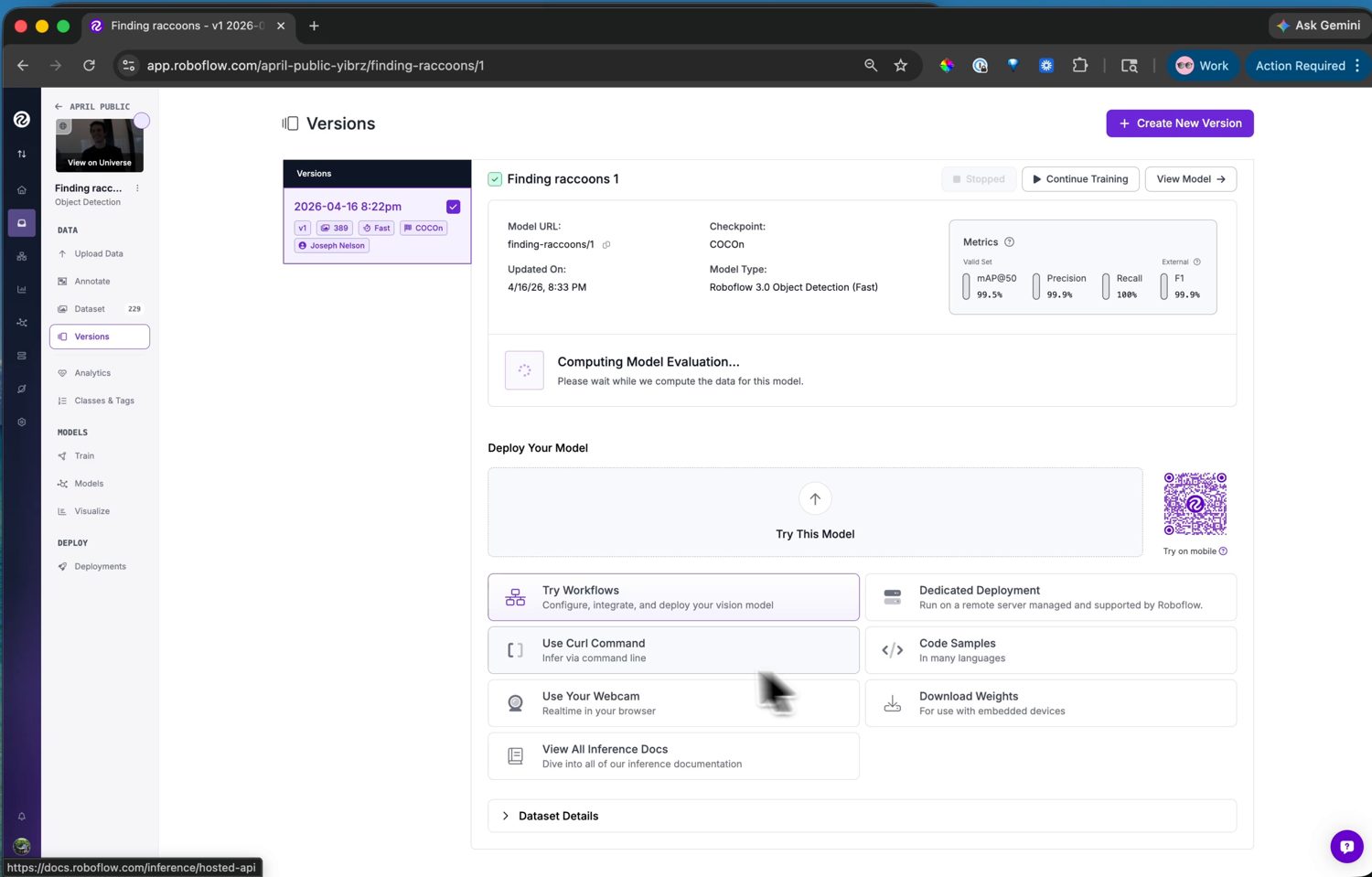
Das trainierte Modell mit seinen Genauigkeitsmetriken. Von hier aus führt die Seite Visualize es auch an Testbildern oder einer Webcam für eine schnelle Plausibilitätsprüfung aus.¶
Wenn die Zahlen gut sind, ist das Modell bereit zur Bereitstellung. Wenn nicht, besteht die Lösung meist in mehr oder vielfältigeren Daten – nehmen Sie einen weiteren Clip auf, beschriften Sie ihn und trainieren Sie eine neue Version.