13.7.4. Trenowanie modelu¶
Mając w ręku oznaczony zbiór danych, trenowanie jest prowadzonym przepływem na stronie Train: zablokuj wersję zbioru danych, wybierz architekturę i przekaż uruchomienie serwerom Roboflow.
13.7.4.1. Wersja zbioru danych¶
Przed trenowaniem Roboflow buduje wersję zbioru danych – zamrożony zrzut obrazów wraz z dwiema transformacjami stosowanymi przy wejściu:
Preprocessing zmienia rozmiar każdego obrazu do rozdzielczości, przy której model jest trenowany. Utrzymuj tę rozdzielczość małą: kamera uruchamia małe modele, a detektor wytrenowany przy umiarkowanej rozdzielczości mieści się w pamięci kamery i działa szybko.
Augmentation syntetyzuje dodatkowe obrazy treningowe poprzez zaburzanie oryginałów – odbicia, zmiany jasności i ekspozycji, rozmycie, szum. Każda augmentacja uczy model tolerowania rzeczywistej zmienności, którą napotka na kamerze, co znacznie wydłuża zasięg małego, ręcznie przechwyconego zbioru danych.
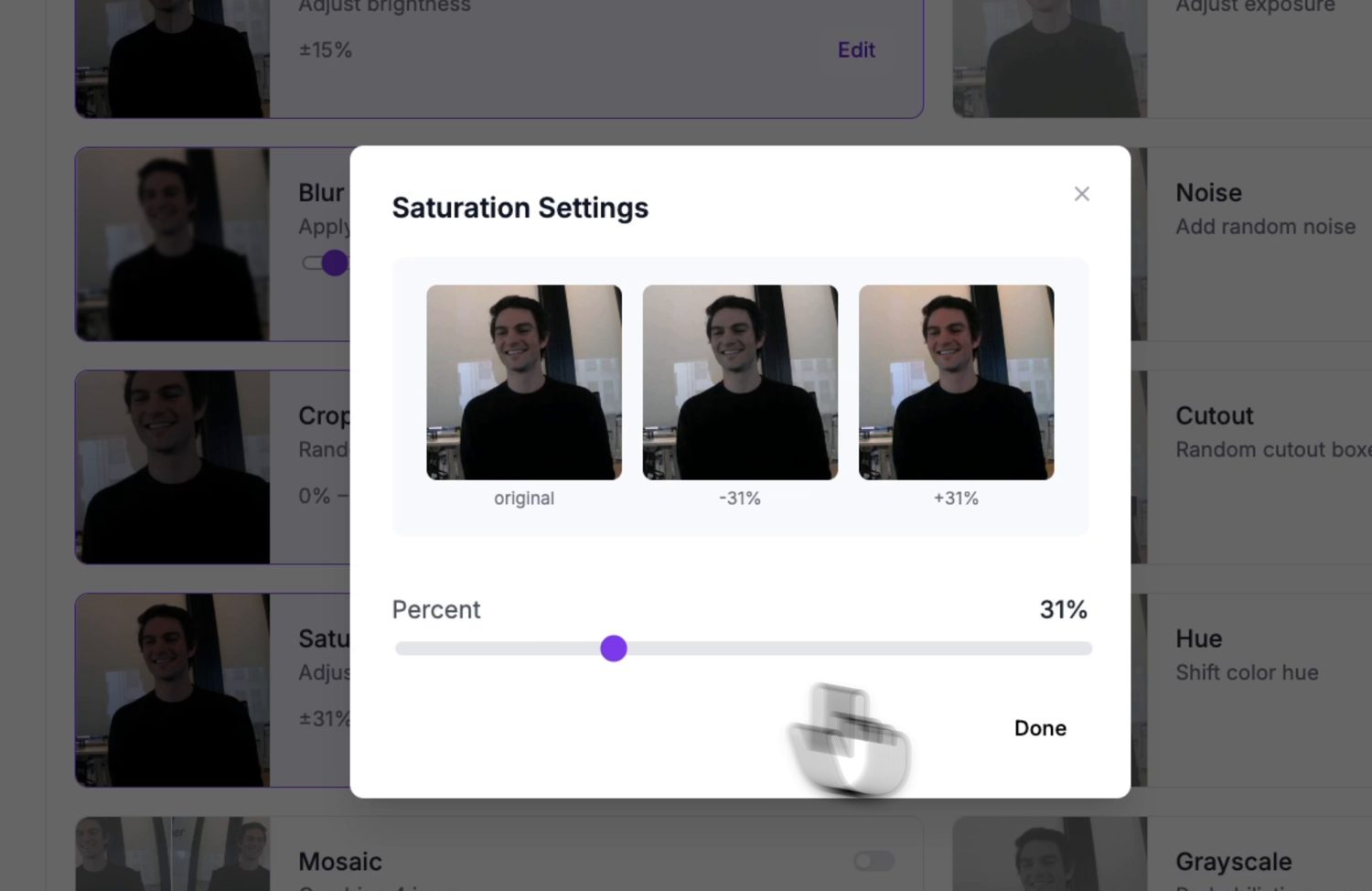
Podgląd augmentacji: każda opcja pokazuje, co robi z przykładowym obrazem, zanim zatwierdzisz ją do wersji.¶
Dopasuj augmentacje do zmienności, jaką kamera faktycznie zobaczy. Jasność i ekspozycja zasługują na swoje miejsce – oświetlenie zmienia się nieustannie. Pomiń te, które nigdy nie wystąpią w twoim ustawieniu; kamera przymocowana na stałe nigdy nie zobaczy pionowego odbicia, więc augmentacja odbicia jedynie rozcieńcza zbiór danych.
13.7.4.2. Wybór architektury¶
Następnie wybierz architekturę modelu. Roboflow oferuje kilka, każda z selektorem rozmiaru, który równoważy dokładność względem szybkości.
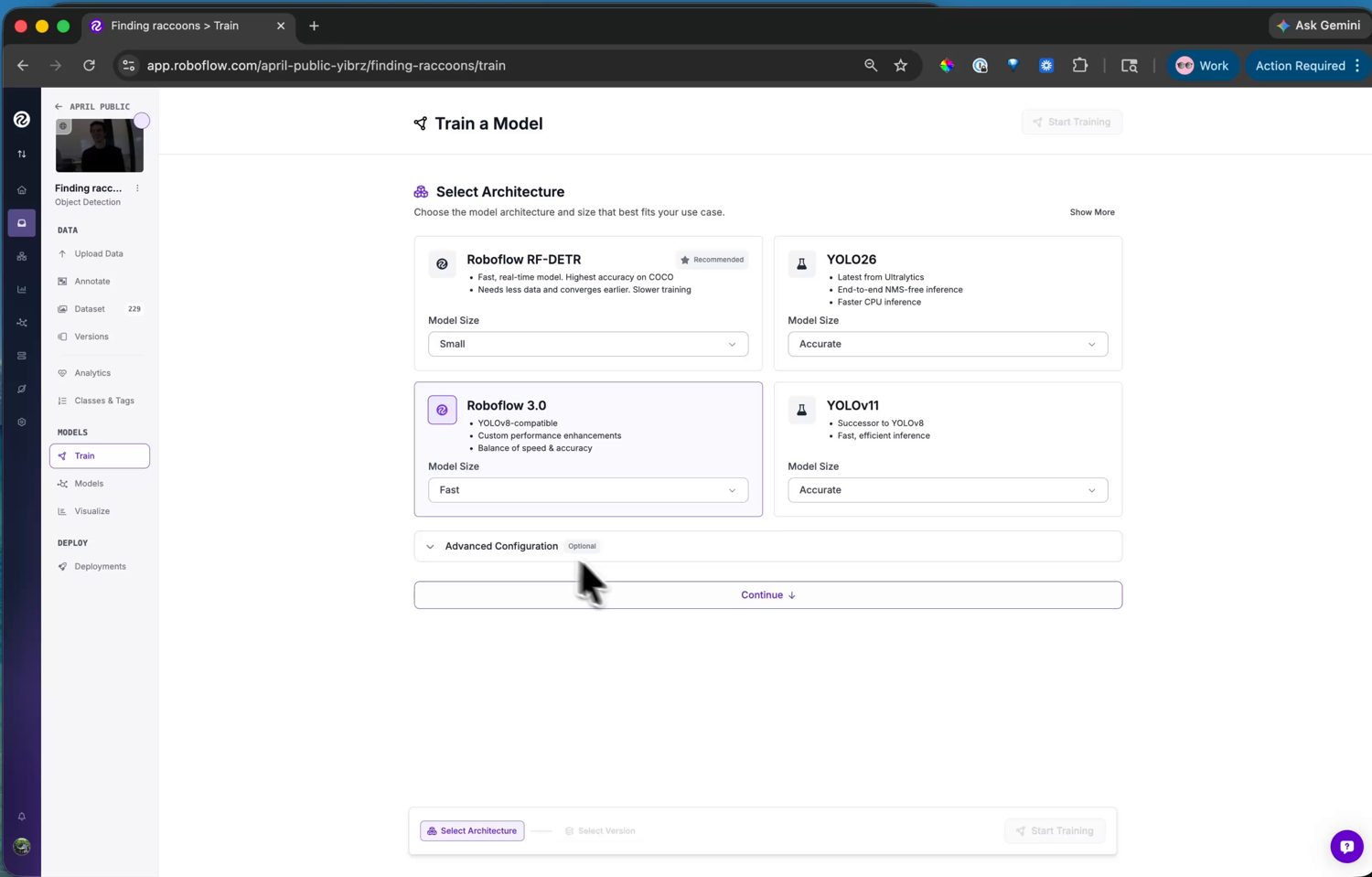
Wybory architektury – każda z selektorem rozmiaru, który równoważy dokładność względem szybkości wnioskowania.¶
Dla kamery wybierz Roboflow 3.0. Pod maską jest to YOLOv8, a kamera dostarcza postprocesor YOLOv8 w ml.postprocessing.ultralytics, więc jego wyjście dekoduje się bez dodatkowego kodu z twojej strony. Wybierz rozmiar Fast – mieści się w pamięci kamery i działa z użyteczną liczbą klatek na sekundę.
13.7.4.3. Uruchamianie trenowania¶
Rozpocznij uruchomienie, a trenowanie odbywa się na serwerach Roboflow – zwykle znacznie poniżej godziny dla małego zbioru danych, z e-mailem po zakończeniu. Strona wersji pokazuje następnie wykresy trenowania oraz metryki dokładności: mAP, precyzję i czułość.
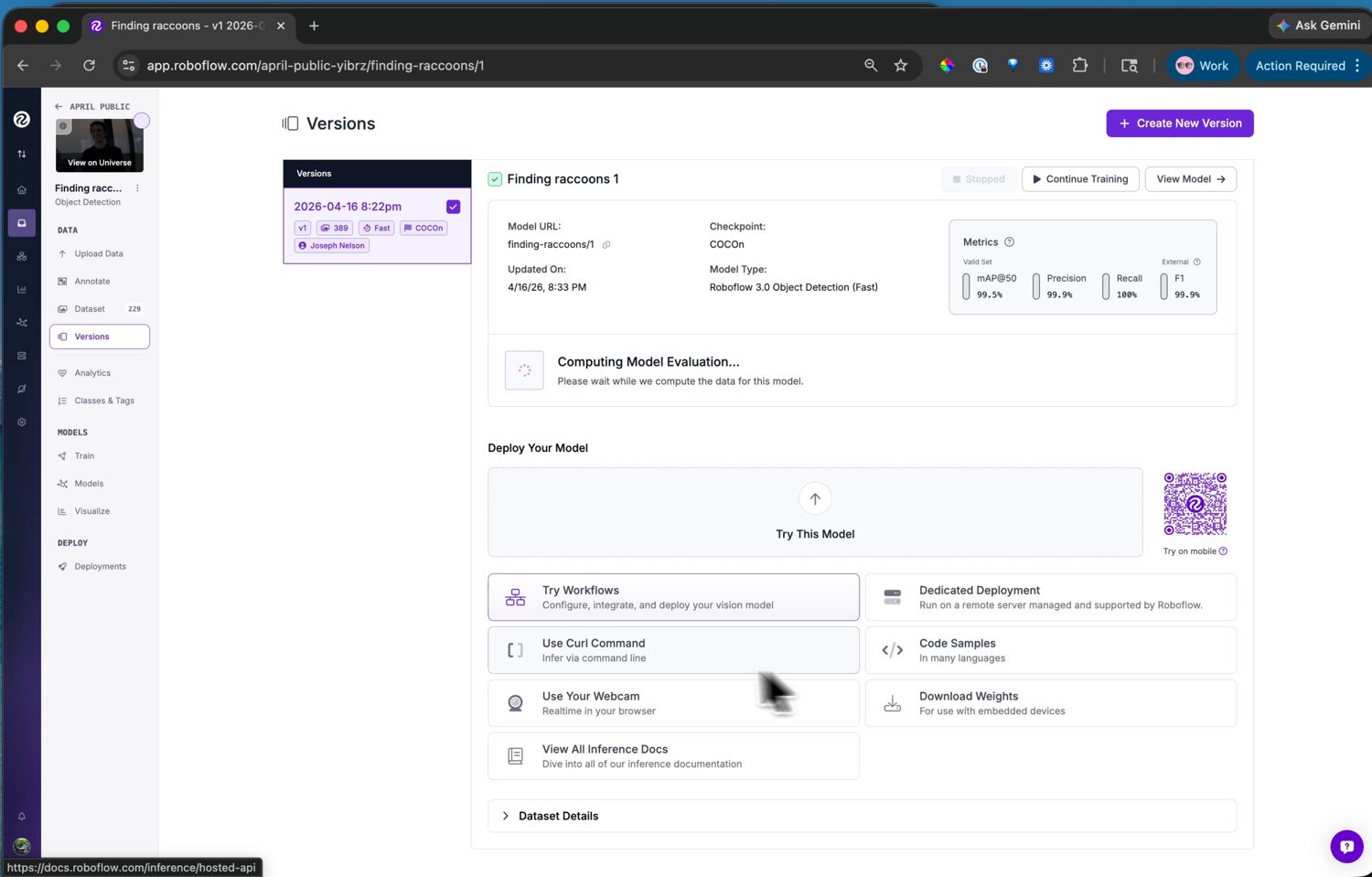
Wytrenowany model wraz z jego metrykami dokładności. Stąd strona Visualize uruchamia go również na obrazach testowych lub kamerze internetowej w celu szybkiego sprawdzenia poprawności.¶
Jeśli liczby są dobre, model jest gotowy do wdrożenia. Jeśli nie, rozwiązaniem jest zwykle więcej lub bardziej zróżnicowanych danych – nagraj kolejny klip, oznacz go i wytrenuj nową wersję.